We begin with data discovery, profiling, and cleansing, resolving quality issues such as missing values, inconsistent formats, and outliers that can distort model behaviour.
- Data source inventory and lineage
- Data quality rules and thresholds
- Standardisation and normalisation
We design and evaluate candidate features that capture domain knowledge, behavioural patterns, seasonality, and external drivers to maximise predictive power while avoiding unnecessary complexity.
- Derived metrics and ratios
- Time-based and cohort features
- Dimensionality reduction where appropriate
From interpretable classical models to high-performance ensembles, we evaluate multiple algorithms, tuning hyperparameters and training repeatedly to find the optimal balance of accuracy, stability, and explainability.
- Clear success metrics agreed with stakeholders
- Cross-validation to mitigate overfitting
- Fairness and bias checks where relevant
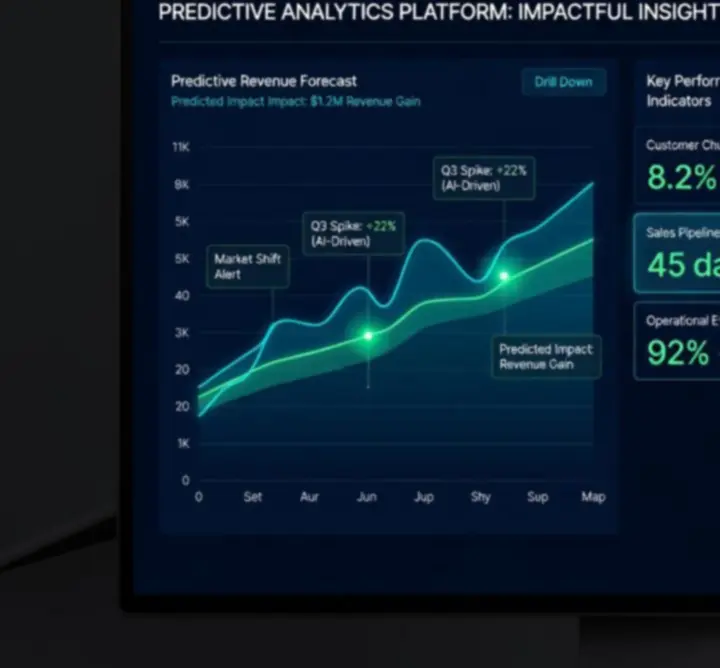
We challenge models with holdout datasets, back-testing, and scenario stress testing to understand how they perform under different market, operational, or behavioural conditions.
- Out-of-time validation
- Performance benchmarking against baselines
- Sensitivity analysis and drift checks
Our team documents assumptions, constraints, and monitoring plans, while packaging models for integration into your architecture with clear handover artefacts.
- Model cards and technical runbooks
- Reproducible training pipelines
- Governance and approval workflows